Understanding Edge Computing: A Topology Based Taxonomy
- August 30, 2019

“What is edge computing?” This question is becoming more and more relevant. The explosion of data-generating endpoints (IoT) and data-hungry user services (video entertainment, intelligent consumer services, etc.) has reversed the centralized intelligence trend, and prompted a shift toward distributed intelligence. Transmitting all the data to public cloud or centralized data center is no longer the norm. Around 10% of enterprise-generated data is created and processed outside a traditional centralized data center or public cloud. By 2025, Gartner predicts this figure will reach 75%.[1]
“Edge computing”, a popular buzzword, is a term filled with market opportunity and ambiguity. It means different things to different folks depending on the context of each deployment. Following this whitespace since 2017, I’ve crystallized understanding “edge computing” in the market and technology contexts.
Simply put, edge computing is computing (and associated storage, networking) at the edge of the network, near/on the endpoints. Linux Foundation defines edge computing as, “The delivery of computing capabilities to the logical extremes of a network in order to improve the performance, operating cost and reliability of applications and services.”[2] Gartner defines edge computing as “solutions that facilitate data processing at or near the source of data generation.”[3]
Armed with the above understanding, we’ll map it on real-world data flow following IT/network topology. The following is a high-level systems representation of edge computing:
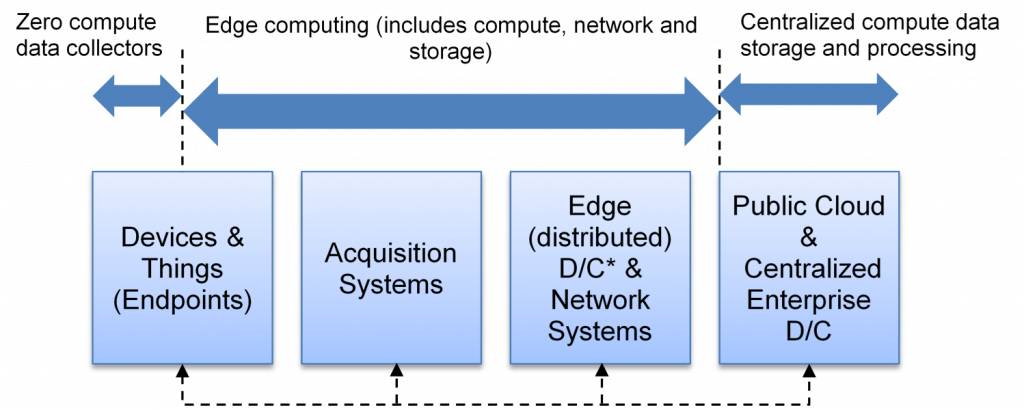
We’ll start with the data creators, which are typically endpoints such as sensors, mobile phone devices, etc. These form the extreme edge of the network. Some endpoints have embedded compute such as mobile phones, while others just generate and transmit data. The ones with compute start forming edge compute.
Data from the endpoints then have the options to flow through nearby gateways, or a Wi-Fi/W-LAN (SD-WAN) router/equipment, or the telco tower/rooftop towers. These form acquisition systems, which aggregate data and perform data condensing functions. They usually have some level of processing capability. Their main job is to collect the data from various endpoints and send upstream, or vice versa. In this step, they also usually perform some low-level data processing, such as data filtering (which determines what data is sent/blocked) and data analytics. Hence, most of the acquisition systems come under edge computing.
Data then flows from “acquisition systems” to closer edge datacenters and network systems. These can be micro-datacenters on a factory shop floor, a CDN’s edge PoP (Point of Presence) or an edge colocation local or a metro regional datacenter for a Telco or IT Service Provider. These also include local containerized datacenters for enterprise ROBO (Remote Office Branch Office). These edge datacenters perform significant compute; driving real and near-real-time analytics. The results of these analytics are that new output data is generated. Such outputs are either sent back down to endpoints for some action/view or sent up the network to centralized datacenters/public cloud.
Centralized datacenters or public cloud can be looked at as centralized storage and compute. The data is warehoused, and big-data analytics can be run with the large amounts of data stored.
Earlier, the data flowed from “acquisition systems” directly to regional, then to centralized datacenters, or directly to centralized datacenters or public cloud over internet/LAN connection. As we noted, the purpose was to (and still, in some cases) warehouse the data generated in a centralized location. This data stored would then be used to drive analytics. What’s changing now is the data explosion and growing hunger to drive near real-time analytics. This led to prohibitive data movement costs and network bandwidth, giving rise to new interesting edge datacenter form-factors. It’s fascinating that most of the edge deployment is unique to its use cases around analytics, content delivery and connectivity across industries—this may cause confusion to those trying to understand edge computing. When we zoom out from a topology perspective, edge computing is the computing available between zero-computing endpoints to centralized datacenters & public cloud.
Check back next month for a deeper dive on edge computing taxonomy. We’ll break down the edge datacenters and network systems (distributed).
In the meantime, check out this blog for more on edge computing and the edge ecosystem.
[1] Gartner, What Edge Computing Means for Infrastructure and Operations Leaders
[2] Linux Foundation, Open Glossary of Edge Computing
[3] Gartner, What Edge Computing Means for Infrastructure and Operations Leaders