Hadoop Is Growing Up.
- August 10, 2017

As a part of my regular duties, my job is to pay attention to macro-level movements of various industries and technology sectors. One of those sectors is facing some rather large tectonic shifts as of late is the emerging and rapidly growing sector often referred to as big data. More specifically, the topic is Hadoop.
Hadoop is much decried as being too hard to implement, and many complain about the lack of talent and expertise in Hadoop. Much of this is overblown, but it is undoubtedly true that running the network and compute on 10,000 nodes of Hadoop is FAR more difficult than running a lab of 10 Hadoop nodes with 3 master nodes. The level of complexity past 1,000 Hadoop nodes is a logarithmical curve. It is also true that hiring polymath talent to do all things Hadoop is very competitive.
Lately, there have been some very interesting polls and studies around organizational interests in Hadoop, as well as benchmark studies that line up with that interest. IDC released a customer survey last year that made it into my hands a few months ago (Source: IDC, Hadoop Adoption Rationale and Expectations, September 2016). Based on responses from 219 private and public sector organizations in the U.S., the results in this IDC poll showed a very interesting quandary:
The most popular architecture for Hadoop was centralized enterprise storage (selected by more than 35 percent of survey respondents who indicated they were considering or had already deployed Hadoop). However, performance was the number one primary driver for selecting a Hadoop architecture (indicated by more than 50 percent of respondents).
Based on this data, it’s clear that enterprises want enterprise storage for Hadoop and they are also very concerned about performance. This is a contraction to the traditional Hadoop reference architecture from just a few years ago (i.e. direct-attached storage).
Indeed, now when I talk to our customers about their hopes for Hadoop, they talk about the need for enterprise features, ease of management, and Quality of Service. These are the signs of Hadoop moving out of its infancy and awkward teenage years, and becoming part of a more mature enterprise technology sector.
Intel also recently released a performance benchmark study that showed no performance slowdown for Hadoop when run in Docker containers. This too is fascinating.
The benchmark study shows that performance for Hadoop on the container-based software platform from one of Dell EMC’s partners, BlueData, now rivals the performance of a bare-metal Hadoop instance. The BlueData platform also provides enterprise security and multi-tenancy for large-scale containerized Hadoop deployments. Again, the traditional reference architecture for Hadoop has historically been all about bare-metal clusters; containerized Hadoop was perceived as potentially slower, less secure, and/or not scalable. The study’s findings clearly fly in the face of “conventional wisdom” for Hadoop.
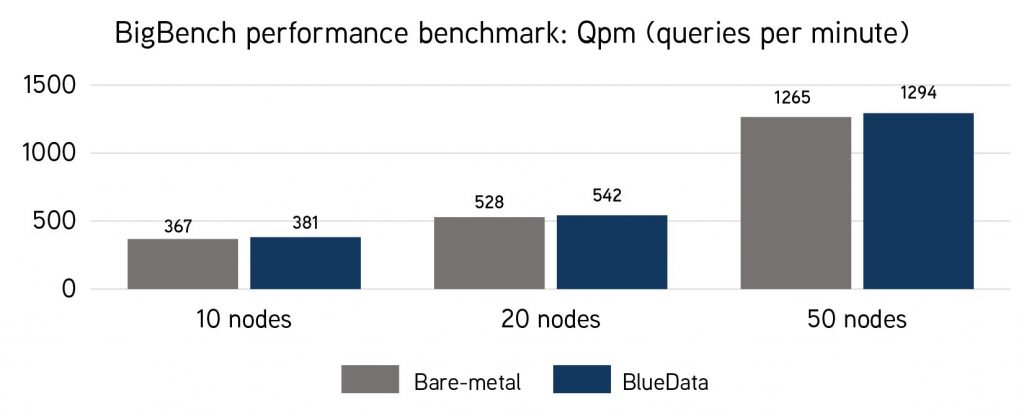
[The chart above shows the overall performance of containerized Hadoop running on the BlueData software platform compared to Hadoop on bare-metal for 10, 20, and 50 node clusters. In this case, higher is better].
From a Dell EMC Isilon perspective, we have responded to the same sentiment illustrated in this study. Our new Gen6 Isilon comes with 11 times the throughput of previous models. This can be seen in an increased backplane and the 40 Gb network cards achieves > 15 GB per second per 4U chassis on the all flash model and > 12 GB per second per 4U chassis on a spinning disk model. The ability to pair greater performance on a centralized scale-out storage platform helps to make that apparent disparity in the IDC polls more realistic.
If I pause and consider these things in tandem, the thought that comes to my mind is that Hadoop is really starting to grow up. Customers are increasingly seeking enterprise-grade, IT-based capabilities such as backups, redundant clusters, and better storage efficiency (versus the triple-mirroring of traditional Hadoop deployments). And they are looking to achieve operational efficiencies by using their existing staffing and technology investments.
The benefits of a containerized solution such as BlueData can help in this regard, by delivering the on-demand elasticity of Big-Data-as-a-Service in an on-premise or hybrid deployment model. It’s now possible to spin up instant Hadoop clusters for short-term usage (e.g. special jobs or special projects), while tapping into data from shared enterprise storage. And secure multi-tenancy with fully containerized clusters for Quality of Service amongst different Hadoop users is now viable. All of this defies the conventional wisdom of running Hadoop on bare-metal with “pizza box” servers, supported by a few polymaths in a lab.
Let’s tease this apart a bit more. If we build a stack that corresponds to the IDC poll and the Intel benchmark study, we have containerized Hadoop on shared storage and commodity compute with no special storage subsystem needs. From an operational perspective, we could peel back more layers of that onion to reveal additional opportunities: The storage team could manage the centralized storage, the DBAs could manage Hadoop, he server team could manage the compute (using BlueData’s software to manage containerized Hadoop) along with their other servers. And with BlueData, the data science teams and analysts get instant access to the Hadoop-based environments they need without having to understand the underlying infrastructure and operations. This seems to remove some of the concerns around Hadoop operations and the elusive hunt for unicorn polymaths to run the whole stack. Federation of the pieces could easily be supported by almost any internal IT team or outsourced provider.
Peeling back the layers of this onion even further, the density of shared storage and the use of containerized compute shrinks the footprint of a Hadoop environment. Rows and rows of Hadoop nodes can be condensed into a manageable set of cabinets. Containerization and multi-tenancy delivers the potential for Quality of Service and mini-clusters. This removes the dependency on massive clusters with a few master nodes. (The 10,000 nodes to five master nodes brings other challenges, but I can tackle that in another blog…)
Maybe Hadoop really is growing up. Dell EMC and our partner BlueData see a lot of demand for this type of architecture as of late. In fact, we conducted a recent webinar together (you can watch the replay here) to help companies avoid common mistakes and outlined new best practices for Hadoop in the enterprise. If you have any feedback, thoughts, or questions, please feel free to ping me on Twitter @KeithManthey.