FPGA’s – Use Cases in the Data Center
- August 26, 2017


I’m on the road quite a bit and get the opportunity to engage many customers on a range of topics and problems. These discussions provide direct feedback that helps the Server team focus on customer- oriented problems and potential challenges vs. creating technology looking for a home. In earlier blogs, I mentioned how the performance CAGR was not keeping up at the same time we had new emerging problems.
Previously, we believed the impact of Moore’s Law on FPGA’s (Field Programmable Gate Arrays) would be more profound than ever – prior it seemed FPGAs were never quite big enough, couldn’t run fast enough and were difficult to program. Technology moves quickly and those attributes of FPGAs have changed lot – they are certainly big enough now, clock rates are up, you can even get an embedded ARM core, and lastly the programming has improved a lot. OpenCL has made it easier and more portable – NOTE: I said easier NOT easy – but the results for the right problem makes it worthwhile.
Let me do some context setting on where FPGAs work best – this is not an absolute but rather some high-level guidance. If we take a step back, it’s clear that we’ve been operating in a world of Compute Intensive problems – meaning, problems and data that you can move to the compute because you are going to crunch on it for a result. Generally, this has been a lot of structured data, convergence algorithms and complex math, and general purpose x86 has been awesome at these problems. Also, sometimes we throw GPUs at the problem – especially in life science problems.
But, there is a law of opposites. The opposite of Compute Intensive is Data Intensive. Data Intensive is simple data that is unstructured and only used for simple operations. In this case, we want the compute and simple operators to move as close to the data as possible. For example, if you’re trying to count the number of blue balls in a bucket that’s a pretty simple operation that’s data intensive – you’re not trying to compute the next digit of π. Computing the average size of each ball in the bucket would be more compute intensive.
The law of opposites for general purpose compute is optimized compute…that one is easy. So, the X-Y coordinate 4 world approximately looks like below showing where various technologies best fit.
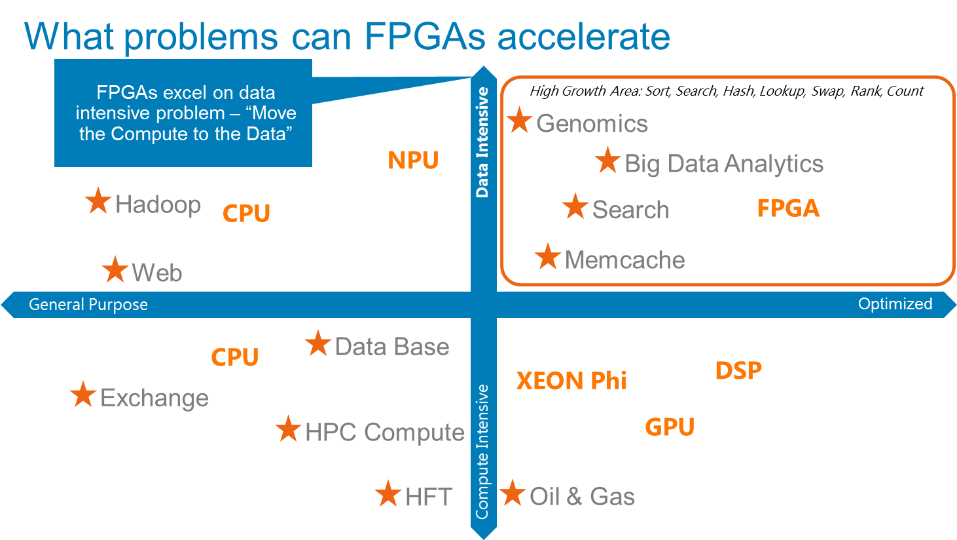
But why are CPUs not great for everything, and why are we talking about FPGAs today? Well, CPUs are very memory-cache hierarchical centric to get data in and out from DRAM to Cache to registers for the CPU to do an operation – as it takes just as much data movement to do complex math as simple math with a general purpose CPU. In this new world of big unstructured data that memory-cache hierarchy can get in the way.
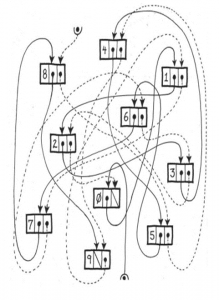 If you think about the link list pointer chasing problem shown to the left here– in a general purpose CPU when you need to traverse the link list every time you do a head/tail pointer fetch due to the data’s unstructured nature you get a cache miss, and thus, the CPU does a cache line fill – generally 8 datum’s. But only the head/tail pointer was needed, which means 7/8th’s of the memory bus bandwidth was wasted on unnecessary accesses – potentially blocking another CPU core from getting datum it needed. Therein lies a big problem for general purpose CPUs in some of these new problems face today.
If you think about the link list pointer chasing problem shown to the left here– in a general purpose CPU when you need to traverse the link list every time you do a head/tail pointer fetch due to the data’s unstructured nature you get a cache miss, and thus, the CPU does a cache line fill – generally 8 datum’s. But only the head/tail pointer was needed, which means 7/8th’s of the memory bus bandwidth was wasted on unnecessary accesses – potentially blocking another CPU core from getting datum it needed. Therein lies a big problem for general purpose CPUs in some of these new problems face today.
Now, let’s focus on some real world examples:
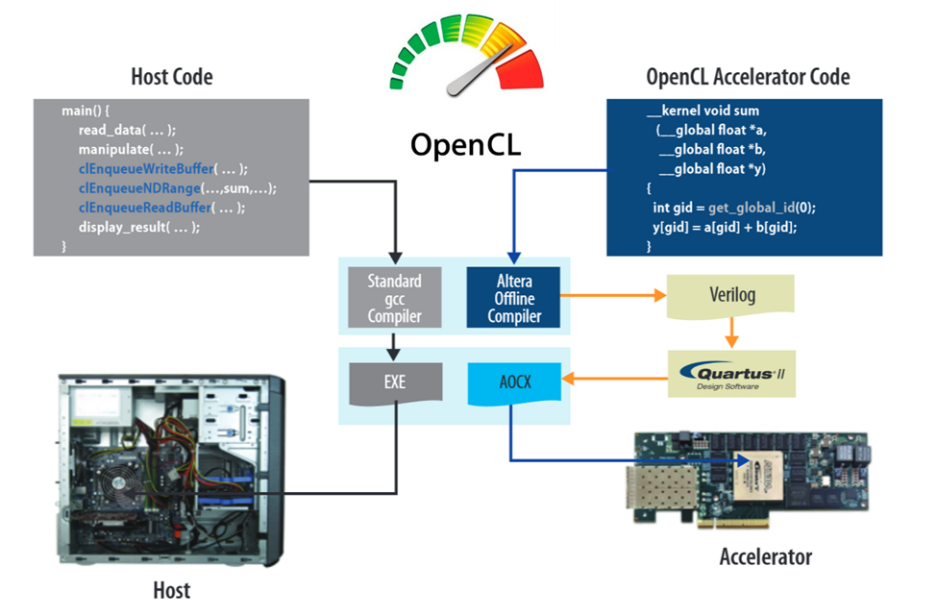
As mentioned earlier, programming is now simpler (simpler – NOT easy). Open Computing Language (OpenCL) is a framework in C++ for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, DSPs, and FPGAs. OpenCL provides a standard interface for parallel computing using task- and data-based parallelism. A quick example and flow is shown below.
Now, I’ll walk you thru two examples that we’ve worked on in the Server Solutions Group to prove out FPGA technology and make sure our server platforms intercept the technology when it’s ready.
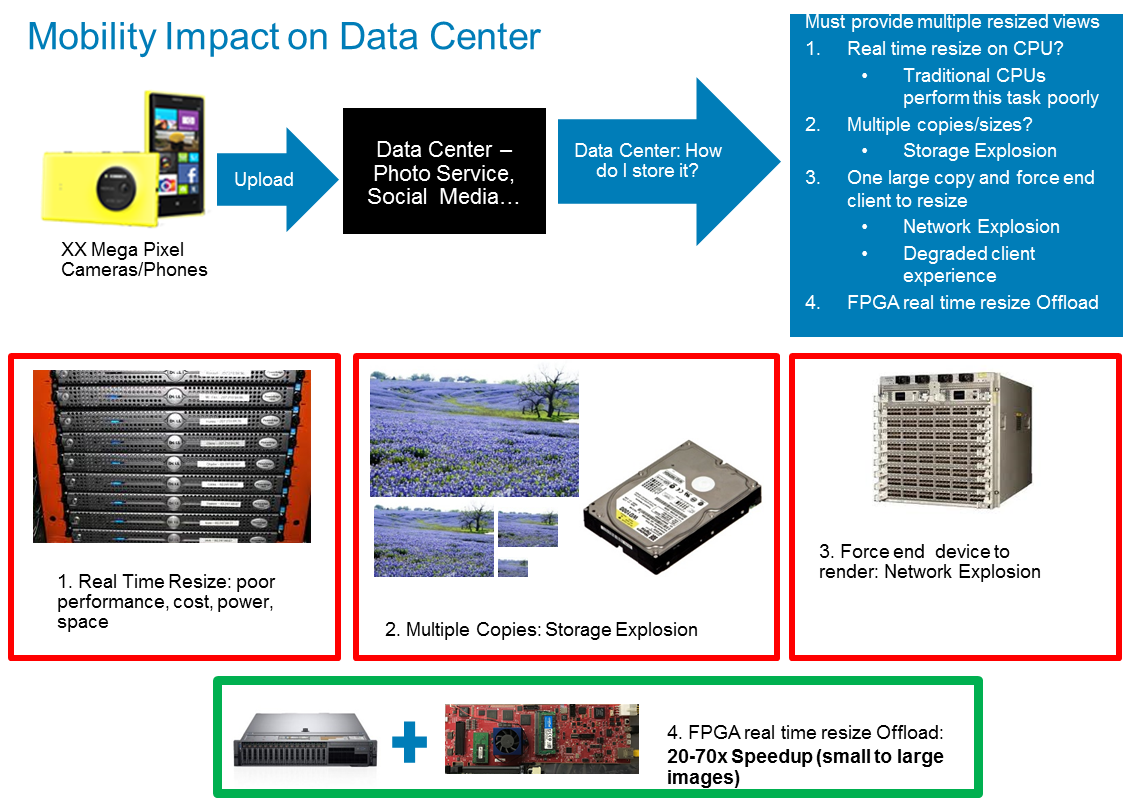
Say you’re a picture gallery site, social media, etc… who want end users to upload full size images from their mega pixel smart phones, so that they can enjoy them on a wide range of devices/screen sizes – how do you solve this problem? The typical approach is using scale out compute and resize as needed for the end device. However, as shown above, it’s not a great fit for general purpose compute, as it scales at a higher cost and you must manage scale out. Other options are batching processes and saving static images of all the sizes you needed – so it becomes a blowout storage problem. Or, force the end user device to resize, but you must send down the entire image – blowing out your network and delivering a poor customer experience.
To avoid any of the above options, we decided to do a real time offload resizing on the FPGA. For large images, we saw around a 70x speedup and about 20x speedup on small images. We replaced 20-70 servers into 1 and saved power, cost, and increased performance – easy TCO. So, now the CPU is handling the request for resized images and delivery but using an FPGA to process the images. Below is high level pictorial.
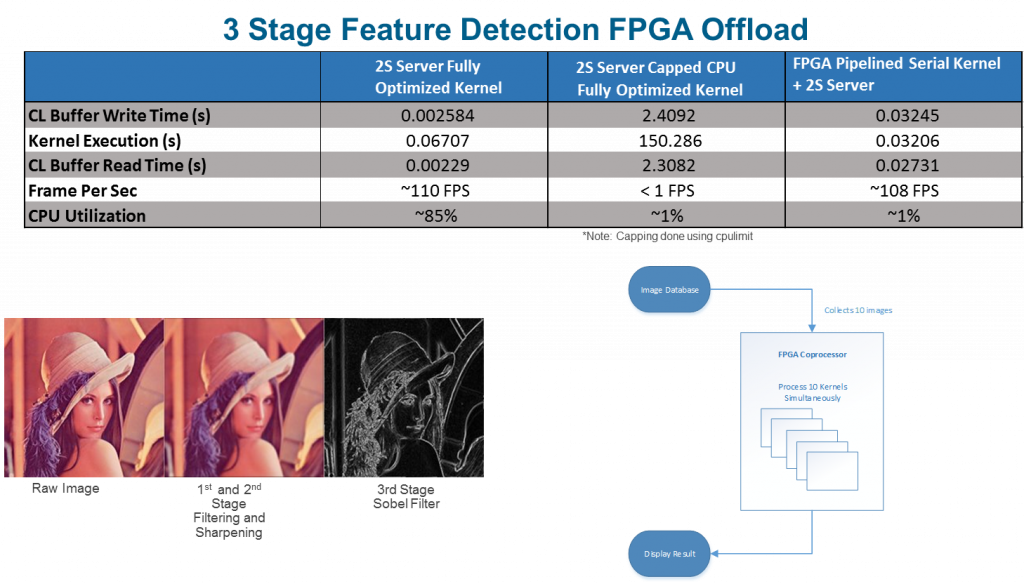
Digital content is everywhere, and we’re moving from text search to image search. Edge detection is an image processing technique for finding the boundaries of objects within images. It works by detecting discontinuities in brightness. Edge detection is also used for image segmentation and data extraction in areas such as image processing, computer vision, and machine vision. In this example, we simply wanted to see what we could accomplish on a CPU and FPGA. We started on the CPU with OpenCL and quickly discovered that the performance was not up to par…. less than 1FPS (frames per second). The compiler was struggling so we manually unrolled the code to swamp every core (all 32 of them) and got up to 110FPS. But at 85% CPU load across 32 cores you could barely move the mouse.
The next step was the same OpenCL code (different #defines) and targeted an FPGA. With the FPGA and parallel nature of the problem we could hit 108FPS. In the FPGA offload case the CPU was ONLY 1% loaded, so we had a server with compute cycles left to do something useful. To experiment, we went back to the CPU and forced a 1% CPU load limit and found we could not even get 1FPS. Point being that in this new world of different compute architectures and emerging problems “it depends” will come up a lot. Below is the data showing the various results I described.
In the future, emerging workloads and use cases (below) will continue to drive the need for new and different compute. Every company will become a data compute company and must optimize for these new uses. If not, they are open to disruption by those who embrace change more aggressively. FPGAs can be a part of this journey when applied to the right problem. Machine learning inference is a great example, along with network protocol acceleration/inspection, image processing as shown, and others can benefit from the reprogrammable nature of FPGAs.
Summary
So, FPGAs can be really useful and can help solve real-world problems. Ultimately, we are heading down a path of more heterogeneous computing where you will hear “it depends” more than you’ll might like. But, as my Dad says, “use the right tool for the right job.” If you have questions about how to use FPGAs in your solutions contact your Dell EMC account rep. Maybe we can help you to.
(The data in this BLOG was made possible by the awesome FPGA team in the Server Solutions Group CTO Office – Duk Kim, Nelson, Mak, Krishna Ramaswamy)