File Interface to AWS Storage Gateway
- April 27, 2017

I should probably have a blog category for “catching up from AWS re:Invent!” Last November we made a really important addition to the AWS Storage Gateway that I was too busy to research and write about at the time.
As a reminder, the Storage Gateway is a multi-protocol storage appliance that fits in between your existing applications and the AWS Cloud. Your applications and your client operating systems see the gateway as (depending on the configuration), a file server, a local disk volume, or a virtual tape library (VTL). Behind the scenes, the gateway uses Amazon Simple Storage Service (S3) for cost-effective, durable, and secure storage. Storage Gateway caches data locally and uses bandwidth management to optimize data transfers.
Storage Gateway is delivered as a self-contained virtual appliance that is easy to install, configure, and run (read the Storage Gateway User Guide to learn more). It allows you to take advantage of the scale, durability, and cost benefits of cloud storage from your existing environment. It reduces the process of moving existing files and directories into S3 to a simple drag and drop (or a CLI-based copy).
As is the case with many AWS services, the Storage Gateway has gained many features since we first launched it in 2012 (The AWS Storage Gateway – Integrate Your Existing On-Premises Applications with AWS Cloud Storage). At launch, the Storage Gateway allowed you to create storage volumes and to attach them as iSCSI devices, with options to store either the entire volume or a cache of the most frequently accessed data in the gateway, all backed by S3. Later, we added support for Virtual Tape Libraries (Create a Virtual Tape Library Using the AWS Storage Gateway). Earlier this year we added read-only file shares, user permission squashing, and scanning for added and removed objects.
New File Interface
At AWS re:Invent we launched a third option, and that’s what I’d like to tell you about today. You can now use the Storage Gateway as a virtual file server that you can mount on your on-premises servers and desktops. After you set it up in your data center or in the cloud, your configured buckets will be available as NFS mount points. Your application simply reads and writes files and directories over NFS; behind the scenes, the gateway turns these operations into object-level requests on your S3 buckets, where they are accessible natively (one S3 object per file). To create a file gateway, you simply visit the Storage Gateway Console, click on Get started, and choose File gateway:
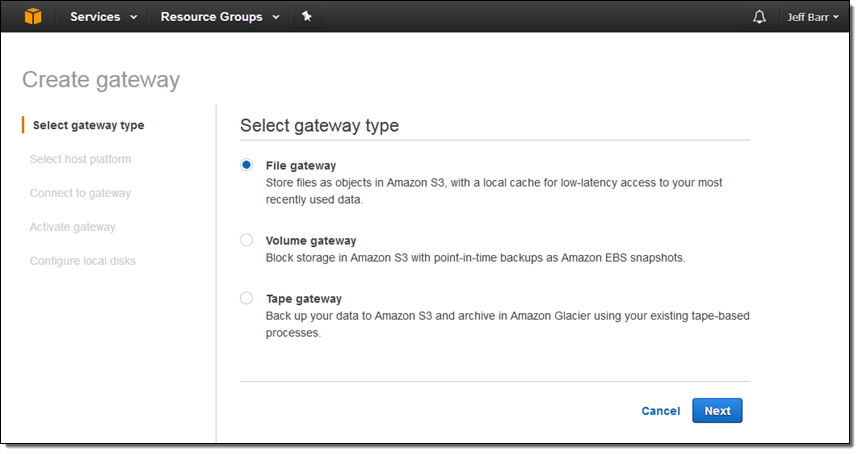
Then choose your host platform: VMware ESXi or Amazon EC2:
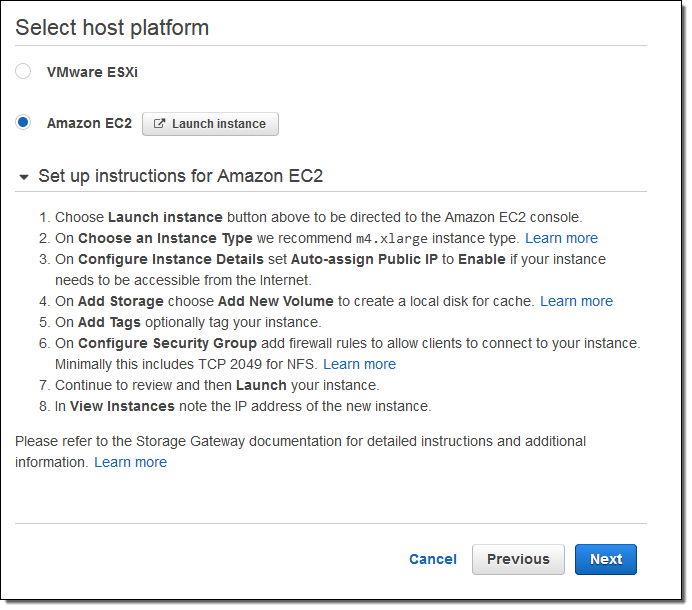
I expect many of our customers to host the Storage Gateway on premises and to use it as a permanent or temporary bridge to the cloud. Use cases for this option include simplified backups, migration, archiving, analytics, storage tiering, and compute-intensive cloud-based processing. Once the data is in the cloud, you can take advantage of many features of S3 including multiple storage tiers (Infrequent Access and Glacier are great for archiving), storage analytics, tagging, and the like.
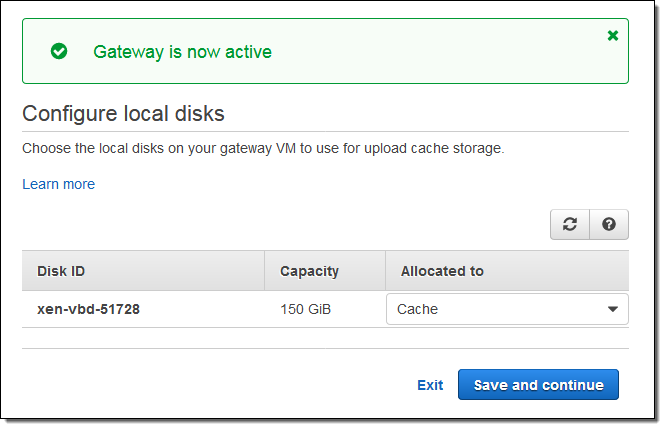
I don’t have much data on-premises so I’m going to run the Storage Gateway on an EC2 instance for this post. I launched the instance and set it up per the instructions on the screen, taking care to create the proper inbound security group rules (port 80 for HTTP access and port 2049 for NFS). I added 150 GiB of General Purpose SSD storage to be used as a cache:
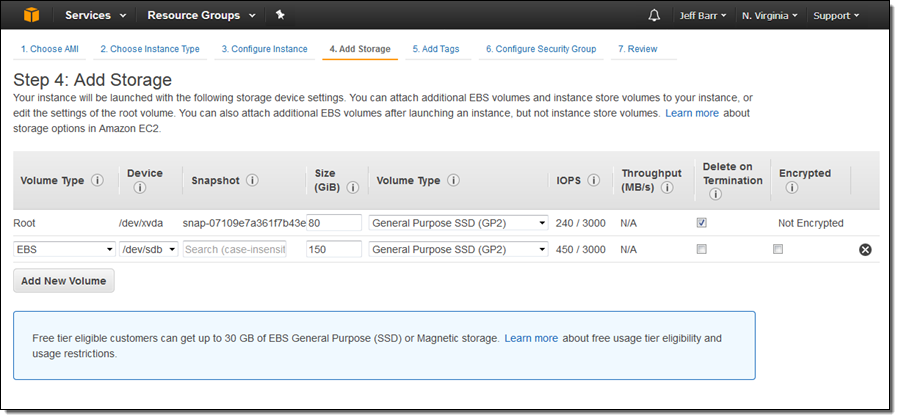
After the instance launched I captured its public IP address and used it to connect to my newly launched gateway:
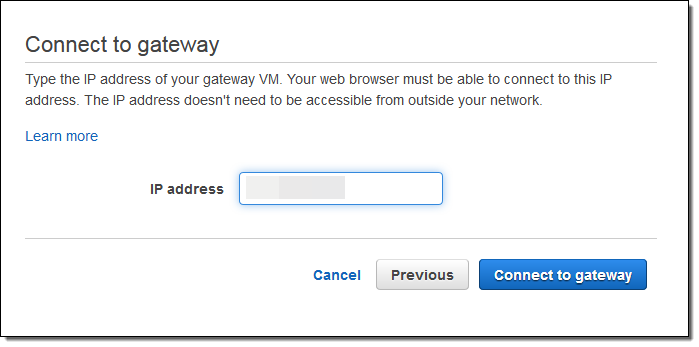
I set the time zone and assigned a name to my gateway and clicked on Activate gateway:
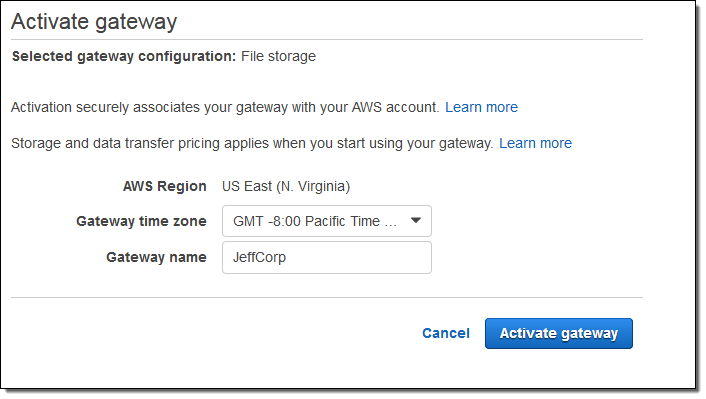
Then I configured the local storage as a cache, and clicked on Save and continue:
My gateway was up and running, and I could see it in the console:
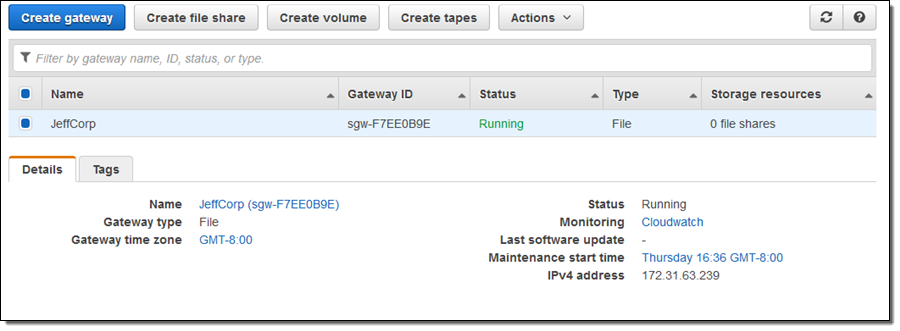
Next, I clicked on Create file share to create an NFS share and associate it with an S3 bucket:
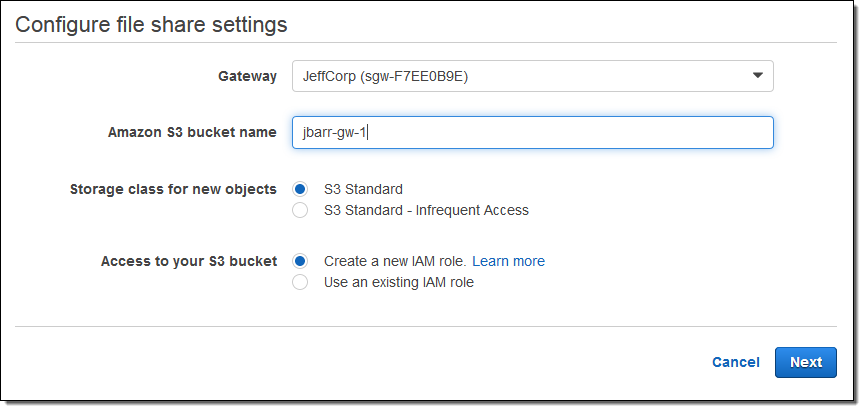
As you can see, I had the opportunity to choose my storage class (Standard or Standard – Infrequent Access in accord with my needs and my use case). The gateway needs to be able to upload files into my bucket; clicking on Create a new IAM role will create a role and a policy (read Granting Access to an Amazon S3 Destination to learn more).
I review my settings and click on Create file share:
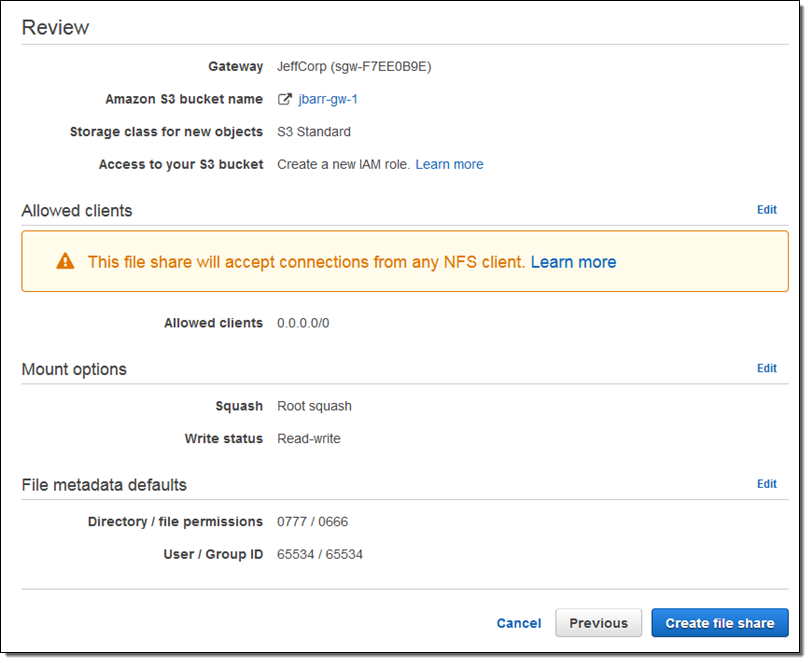
By the way, Root squash is a feature of the AWS Storage Gateway, not a vegetable. When enabled (as it is by default) files that arrive as owned by root (user id 0) are mapped to user id 65534 (traditionally known as nobody). I can also set up default permissions for new files and new directories.
My new share is visible in the console, and available for use within seconds:
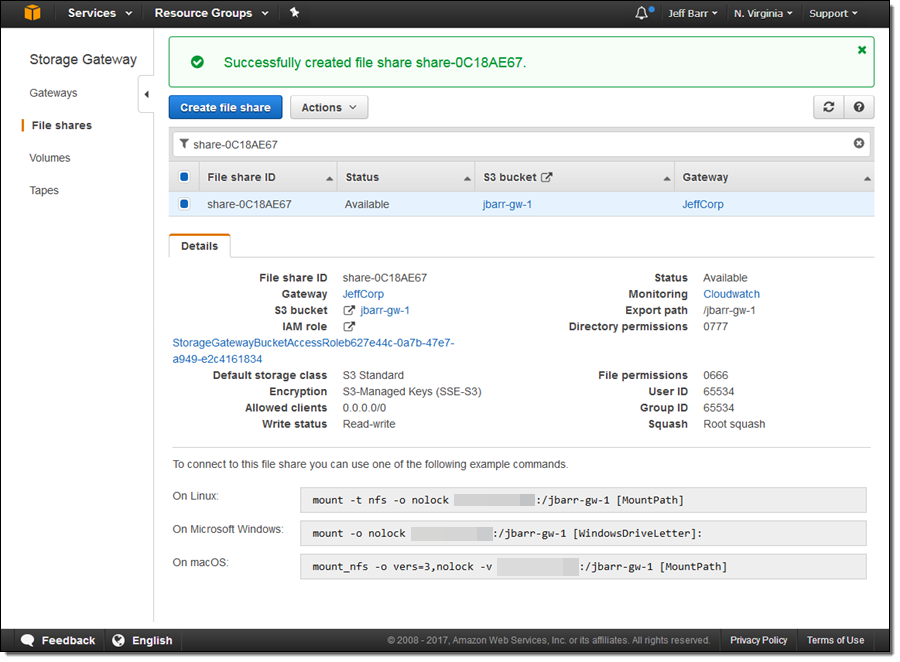
The console displays the appropriate mount commands for Linux, Microsoft Windows, and macOS. Those commands use the private IP address of the instance; in many cases you will want to use the public address instead (needless to say, you should exercise extreme care when you create a public NFS share, and maintain close control over the IP addresses that are allowed to connect).
I flipped over to the S3 console and inspected the bucket (jbarr-gw-1), finding it empty, as expected:
![]()
Then I turned to my EC2 instance, mounted the share, and copied some files to it:
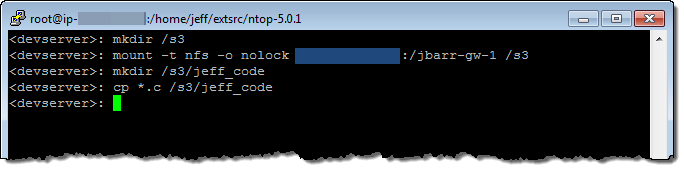
I returned to the console and found a new folder (jeff_code) in my bucket, as expected. I ventured inside and found the files that I had copied to the share:
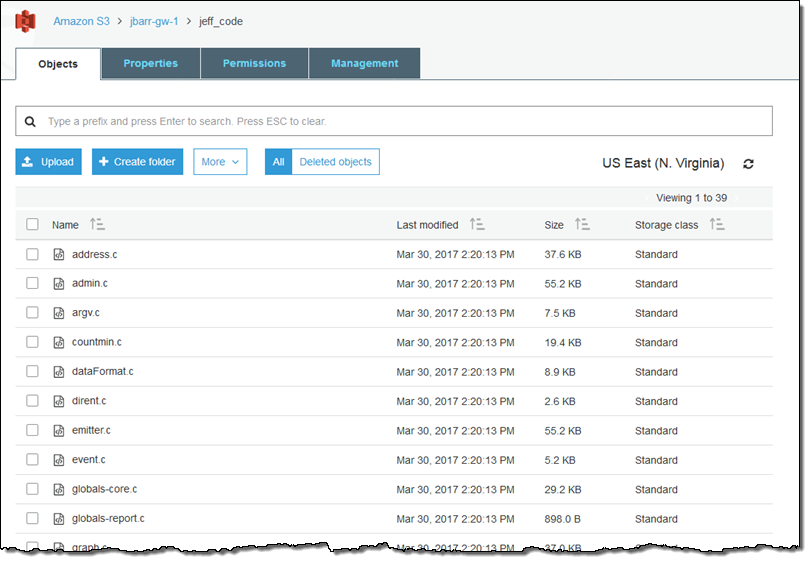
As you can see, my files are copied directly into S3 and are simply regular S3 objects. This means that I can use my existing S3 tools, code, and analytics to process them. For example:
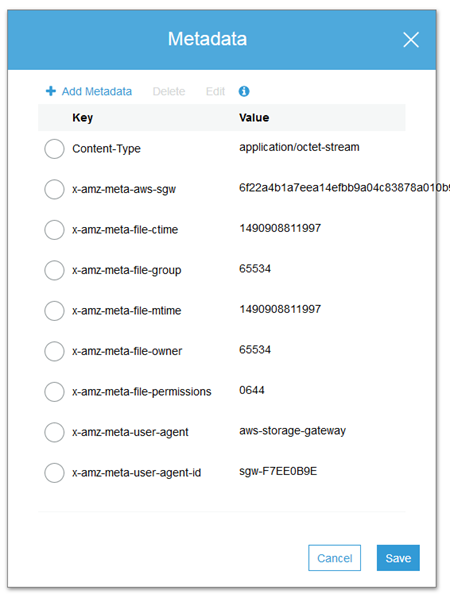
The gateway stores all of the file metadata (owner, group, permissions, and so forth) as S3 metadata:
Storage Gateway Resources
Here are some resources that will help you to learn more about the Storage Gateway:
Presentation – Deep Dive on the AWS Storage Gateway:

White Paper – File Gateway for Hybrid Architectures – Overview and Best Practices:

Recent Videos:
Available Now
This cool AWS feature has been available since last November!
— Jeff;