Accelerate HPC workloads with SAGA – Find out how with Dell EMC Isilon and Altair
- July 9, 2019

An ongoing challenge with HPC workloads is that as the number of concurrent jobs increases, storage reaches a critical point where NFS latency spikes, and beyond that critical point, all workloads are running on that storage crawl. An integration of Dell EMC Isilon scale-out storage with Altair Accelerator enables Storage-Aware Grid Acceleration (SAGA), an elegant and innovative solution that can address your next wave of design challenges.
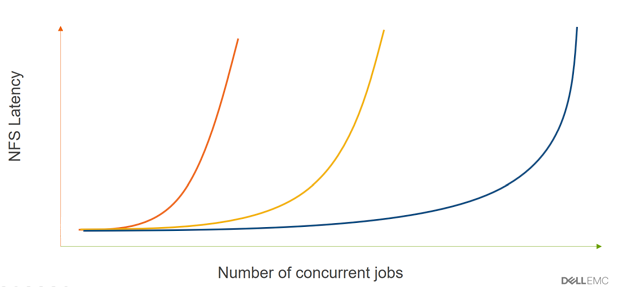
As the number of concurrent jobs in HPC workloads increases, storage latency spikes and workloads start to crawl.
Let us consider a scenario in which you have 10,000 cores in your compute grid and each of your jobs runs 30 minutes, so if you submit 10,000 jobs to the job scheduler, it should be finished in 30 minutes with no jobs waiting in queue. With time, your test cases have grown to 20,000 jobs, and with 10,000 cores that set finishes in 60 minutes. The business need is that you want those 20,000 jobs to finish in 30 minutes, so you add 10,000 more cores. But now, the job doesn’t finish even in 2+ hours because storage latency has spiked from 3ms to 10ms. Latency has x^2 impact on run time, so doubling latency quadruples your average run time.
Let’s now look at another scenario with more I/O-intensive jobs, so just 5,000 concurrent jobs push the NFS latency to that critical point. By adding only 50 more jobs, you would spike the latency to 2x the normal value. And this latency spike doesn’t just affect the additional 50 jobs but the entire 5,050 jobs on the compute grid. Beyond that critical point, there is no value running I/O-intensive jobs on the grid.
In a scale-out Dell EMC Isilon Network Attached Storage architecture you can add more storage nodes and push the critical point to the right so that you can run more concurrent jobs on the compute grid. Remember that workloads are unpredictable, and their I/O profiles can change without much notice.
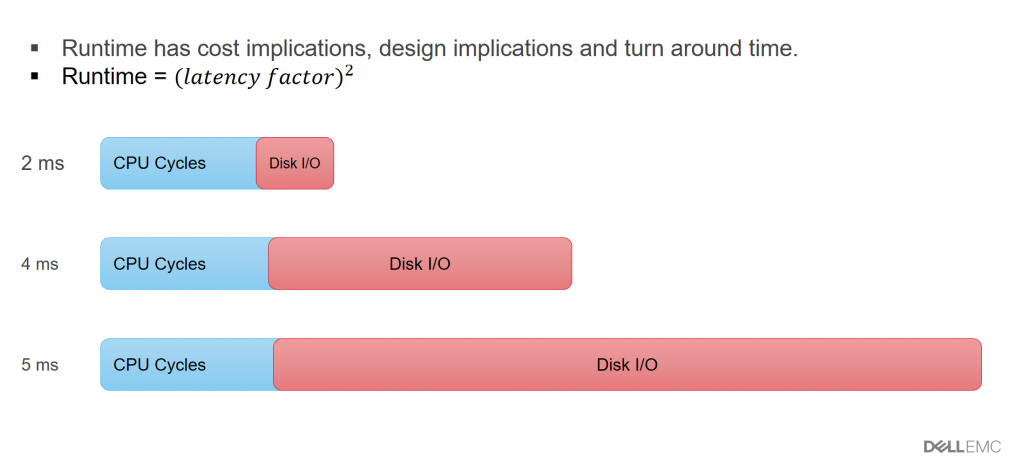
Storage latency greatly impacts runtime of a job, which in turn impacts time to market.
One of the key pieces of the Electronic Design Automation (EDA) infrastructure — or any HPC infrastructure — is a job scheduler that dispatches various workloads to the compute grid. Historically, the workload requirements that are passed on to the job scheduler have been cores, memory, tools, licenses and CPU affinity. What if we add storage as a workload requirement — NFS latency, IOPS and disk usage? Now the job scheduler managing the compute grid is aware of the underlying storage system and can manage job scheduling based on each job’s storage needs, thus accelerating grid throughput by distributing jobs appropriately. Storage is now a resource just like cores, memory, and tools consumed by the workload based on its priority, fair share and limits.
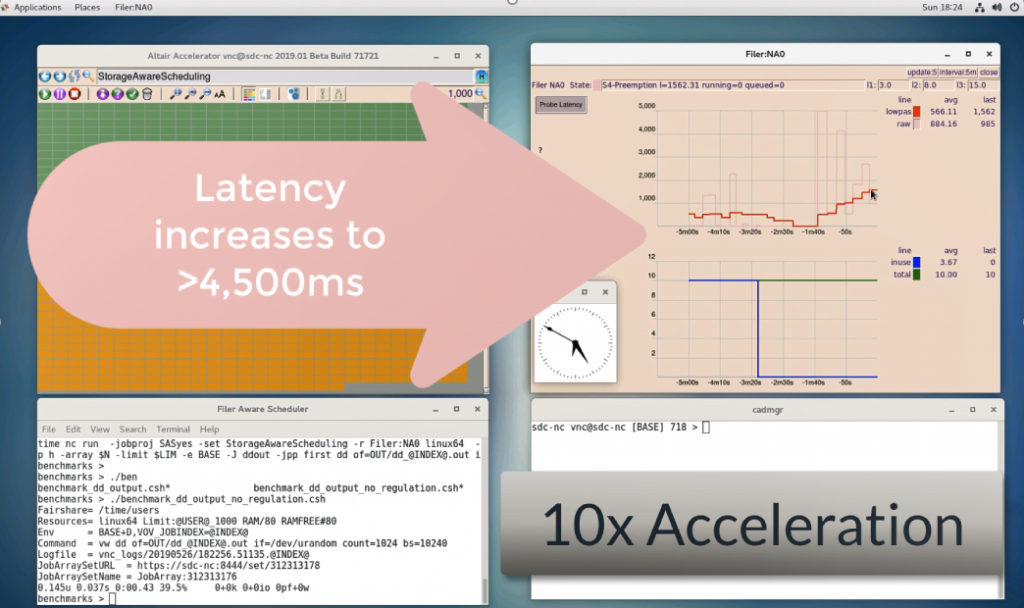
Unmanaged I/O-Intensive jobs cause a dramatic increase in latency.
This simple idea has huge implications on job throughput in the EDA world. As you already know, job throughput impacts design quality and reliability, which in turn impacts tape-outs and ultimately time to market. EDA workloads are massively parallel and as you increase the number of parallel jobs, you put more pressure on the underlying storage system, as it should, but this impact on storage is much more drastic on legacy scale-up storage architectures compared to Isilon, a scale-out storage system. Read more about the benefits of an Isilon scale-out NAS architecture in this white paper.
Storage-Aware Grid Acceleration with Isilon and Altair Accelerator™
With SAGA, you’re throttling and/or distributing jobs that are I/O-intensive as latency spikes beyond a configured value, and now you’re not running 20,000 concurrent jobs but enough so that your jobs finish in 30–45 minutes instead of 4 hours. In addition to 100% throughput gains, you also have substantial indirect cost savings because you’re using 50% fewer licenses and cores. In this example, the numbers are skewed to simplify calculations, but the impact and benefits are similar in the real world.
In the example below, an unmanaged workload of 500 I/O-intensive jobs ran in around 3 minutes on 500 CPUs. When Altair Accelerator was implemented to manage the workload, it ran in the same 3 minutes on only 10 processors — using around 50x fewer resources.
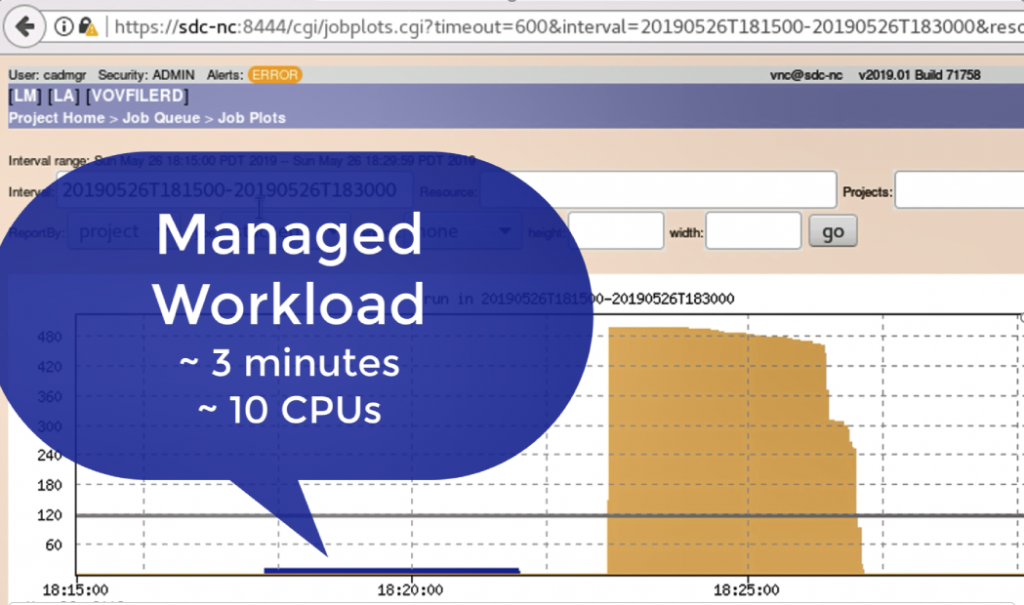
SAGA lets you run your workload with up to 80x less compute resources.
Hot directory detection
Altair Accelerator and Isilon also work together to ensure that filer temperature doesn’t get too hot and compromise performance. Isilon provides feedback to Accelerator, and if an I/O-intensive job needs to be preempted, Accelerator will suspend it.

SAGA lets you identify I/O-intensive jobs and responds by preempting jobs — only those in the hot directory.
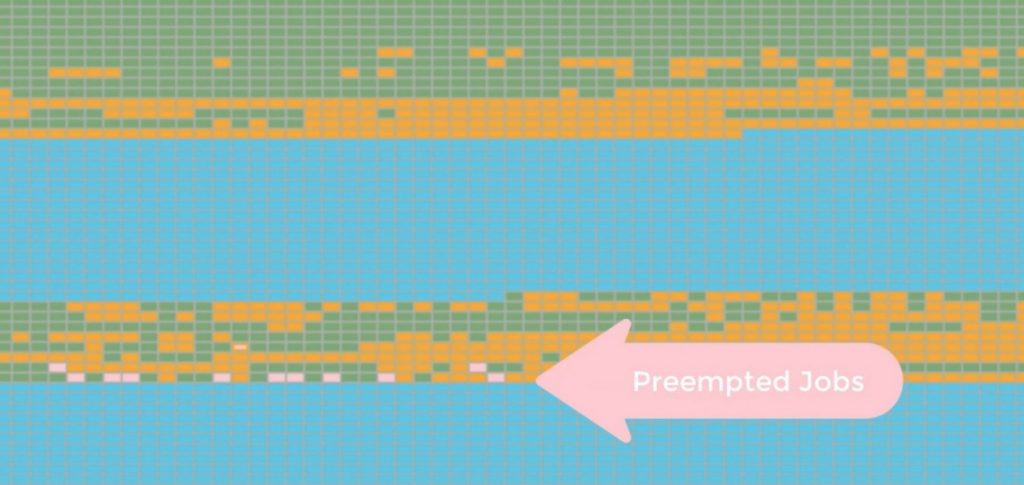
SAGA distributes jobs based on I/O resources and pre-empts I/O intensive jobs in order to maximize job throughput.
Storage is a critical resource
Like cores and memory, storage must be a resource in your grid system, and having a true scale-out storage system like Isilon with an extensive API stack is very valuable. Its integration into Altair’s enterprise-grade Accelerator job scheduler is key to solving the next set of design challenges.
Next steps
Find out today how you can deploy Storage-Aware Grid Acceleration to accelerate your HPC workloads so that high storage latencies don’t slow down your electronic design workloads.
Reach out to your Dell account executive or Altair’s engineering sales team to set up a demonstration of integration between Dell EMC Isilon and Altair Accelerator to enable SAGA.