2018 Server Trends & Observations
- February 15, 2018


This blog was co-authored by Robert W Hormuth, Vice President/Fellow, CTO, Server & Infrastructure Systems and Jimmy Pike, Vice President/Fellow, Server Architect, Server & Infrastructure Systems Office of CTO.
Trends & Observations can serve two purposes. One, a view into a possible state and two, a reflection of things around us that can lead to disruptions. Sometimes you have to look closely to see the trees and other times far away to see the forest.

The customer it turns out, is indeed always right…something we have all heard many times but often forget in the technology world. The winners this year will be technology companies that truly listen and respond to their customers with products, solutions, and services that actually solve customer problems and result in a better business outcome.

2018 will see companies forced to find value in their data or be disrupted by competition that find ways to mine data to create business value and services. Much of this valuation will be done using ML/DL techniques – see #11. 2018 will see both a heightened level of cyber-attacks and a whole new realm of security embedded in the very foundation of the server to protect a customer’s most valuable asset – see #16.
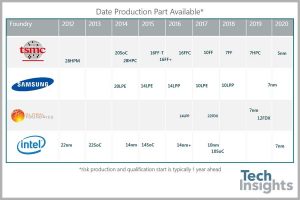
Not a commodity, but rather the various chip makers are at or so near enough to the same process node size that leadership via node size is no longer a differentiator. Thus execution, architectural choices, and proper product definition wins.

Intel, AMD, QUALCOMM, Cavium, and IBM emerge with competitive CPU offerings. Going back to Fabrication Equality as an equalizer. This is healthy for the industry as a whole to enable and drive new innovations that solve real customer problems.
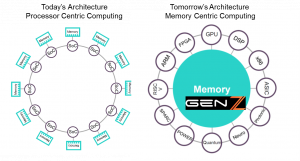
In 2018 the industry will fully conclude we must embrace memory centric computing. This will open up innovation on a variety of fronts on HW and SW. As more devices (FPGAs, Storage Class Memory, ASICs, GPUs…) move into the microsecond to sub-microsecond domain (see Attack of the Killer Microseconds) we can no longer treat these devices as second class citizens behind a thick protocol stack nor can we software define them without losing their intrinsic value. GenZ is gaining greater industry participation as a truly open standard to address this problem. But the first step in any 10 step program is recognition of a problem.


The industry has been on a journey from large SMP Machines to scale out for years. We stopped at 2S, quite frankly, due to a lack of a real single socket optimized CPU. With core counts (32) and memory channels (8) continuing to rise a single socket server is more viable than ever. Dell EMC offers 2 single socket AMD EPYC systems for these reasons (PowerEdge R7415 and PowerEdge R6415).
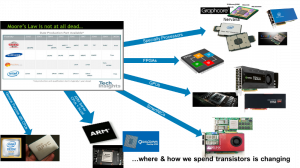 With CPU performance CAGR flat lining on general purpose CPUs and businesses looking to disrupt in the digital transformation ahead of competition, businesses that want to get ahead and stay ahead will turn more toward specialized computing (GPUs, FPGA, ASICs, SmartNICs). Optimized for these new digital big data problems where ML techniques can be used to find the needle in the sea of data. Moore’s Law remember is an economic law, not a performance law, which basically says if you can extract enough value out of a silicon FAB investment you can continue to shrink your FAB about every 2 years. So, where and how we spend those transistors is shifting.
With CPU performance CAGR flat lining on general purpose CPUs and businesses looking to disrupt in the digital transformation ahead of competition, businesses that want to get ahead and stay ahead will turn more toward specialized computing (GPUs, FPGA, ASICs, SmartNICs). Optimized for these new digital big data problems where ML techniques can be used to find the needle in the sea of data. Moore’s Law remember is an economic law, not a performance law, which basically says if you can extract enough value out of a silicon FAB investment you can continue to shrink your FAB about every 2 years. So, where and how we spend those transistors is shifting.
 Thanks for the memories IPMI, after several attempts to standardize infrastructure systems management the industry has finally rallied and succeeded with Redfish. We can thank the founding crew of Dell EMC, HPE, and Emerson for having the vision, patience, and pragmatic approach along with next wave of supporters (MS, VMware, Intel) that took Redfish to the DMTF where a broad set of industry partners are now working together to continue Redfish expansion while SNIA has joined the party with Swordfish for Storage management.
Thanks for the memories IPMI, after several attempts to standardize infrastructure systems management the industry has finally rallied and succeeded with Redfish. We can thank the founding crew of Dell EMC, HPE, and Emerson for having the vision, patience, and pragmatic approach along with next wave of supporters (MS, VMware, Intel) that took Redfish to the DMTF where a broad set of industry partners are now working together to continue Redfish expansion while SNIA has joined the party with Swordfish for Storage management.
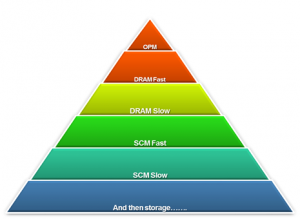 The advent of storage class memory will disrupt server applications, operating systems, and hypervisors. We have to remember though we have spent the last 2 decades pushing scale out and stateless computing. Persistence was once frowned upon to enable application agility, but with the advent of real amounts of cost affective and fast enough persistence things will change as the industry figures out how to use this new technology in due time. The first easy use case will be in storage applications, especially software defined storage. Beyond storage, persistent memory will find a home in large in-memory computing and in Memory Centric architectures that can be disaggregated and composed without trapping this valuable resource.
The advent of storage class memory will disrupt server applications, operating systems, and hypervisors. We have to remember though we have spent the last 2 decades pushing scale out and stateless computing. Persistence was once frowned upon to enable application agility, but with the advent of real amounts of cost affective and fast enough persistence things will change as the industry figures out how to use this new technology in due time. The first easy use case will be in storage applications, especially software defined storage. Beyond storage, persistent memory will find a home in large in-memory computing and in Memory Centric architectures that can be disaggregated and composed without trapping this valuable resource.
 The notion that Servers have become a commodity seems to come and go. But let’s think about it for minute… Commodity by definition is (1) a raw material or primary agricultural product that can be sold, such as copper or coffee (2) a useful or valuable thing, such as water or time. So let’s think about water by way of example – surely we all agree that water is a basic resource and widely available in modern industrialized countries – but is it really a commodity? Checking the shelves at 7-Eleven would seem to indicate that is NOT the case. There are 20+ types; different bottles, purification differences, additives, and so on… so how the commodity (water) is bottled, sold, distributed, filtered… is vastly different. We pay more per gallon for bottled water than gasoline here in the USA. So, water is a commodity, but bottled water is NOT is the net of the story. Now apply that thinking to servers and you find that compute cycles are the commodity (the water) and the server is bottling of those compute cycles. Now that computing is ubiquitous in every toy, IoT device, mobile device….etc…..that makes compute cycles more or less a raw material of our digital lives. What Servers do is bottle commodity compute cycles. How servers bottle up the compute; add Dram, IO, slots, drives, systems management, high availability, density, redundancy, efficiency, serviced, delivered, and warranted in a wrapper of Security….is how they are not a commodity, but are in fact packaging up the real commodity – compute cycles. The fact that the Super7 hyperscalers have not aligned on a common server form factor solidifies these points. So, while we could all drink water from the Hudson, well…
The notion that Servers have become a commodity seems to come and go. But let’s think about it for minute… Commodity by definition is (1) a raw material or primary agricultural product that can be sold, such as copper or coffee (2) a useful or valuable thing, such as water or time. So let’s think about water by way of example – surely we all agree that water is a basic resource and widely available in modern industrialized countries – but is it really a commodity? Checking the shelves at 7-Eleven would seem to indicate that is NOT the case. There are 20+ types; different bottles, purification differences, additives, and so on… so how the commodity (water) is bottled, sold, distributed, filtered… is vastly different. We pay more per gallon for bottled water than gasoline here in the USA. So, water is a commodity, but bottled water is NOT is the net of the story. Now apply that thinking to servers and you find that compute cycles are the commodity (the water) and the server is bottling of those compute cycles. Now that computing is ubiquitous in every toy, IoT device, mobile device….etc…..that makes compute cycles more or less a raw material of our digital lives. What Servers do is bottle commodity compute cycles. How servers bottle up the compute; add Dram, IO, slots, drives, systems management, high availability, density, redundancy, efficiency, serviced, delivered, and warranted in a wrapper of Security….is how they are not a commodity, but are in fact packaging up the real commodity – compute cycles. The fact that the Super7 hyperscalers have not aligned on a common server form factor solidifies these points. So, while we could all drink water from the Hudson, well…
 Business will adopt Machine learning techniques and disrupt or someone else will disrupt them. Hence greater demand for datacenters to become agile, automated and orchestrated while adopting new heterogeneous compute. They will however, begin to recognize that it is a tool and not the answer all problems. This will lead to more practical focus on problems where it excels.
Business will adopt Machine learning techniques and disrupt or someone else will disrupt them. Hence greater demand for datacenters to become agile, automated and orchestrated while adopting new heterogeneous compute. They will however, begin to recognize that it is a tool and not the answer all problems. This will lead to more practical focus on problems where it excels.
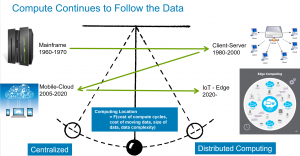 Computing demands have always followed the data; from Mainframe-Terminal, to the Client-Server, Mobile-Cloud, and the emerging IoT-Edge Era. The location of compute has always been based on an economic function Fn(cost of compute cycles, size of data, complexity of data, bandwidth costs). Those variables have driven where we compute since the dawn of computing and will continue into the future. The cost of networking will further begin to drive the realization that not only should compute occur at the edge, but data storage as well. Data should be stored as close as possible to the point of creation. Information from the data may be needed elsewhere, or even replication of some of the data may be elsewhere, but not the general rule. Look for more compute at base stations, retail stores, factories, etc….anywhere large amounts of data is created to make business critical decisions or one wants to create a more real time experience for the consumer. This will also spawn the next generation of hybrid cloud via distribution of processing between edge servers / edge data-centers and centralized data-centers/cloud. The goal will be to find the valuable data near the source (where data is generated), minimize the amount of data that needs to be stored at centralized location (public/private cloud), and deliver results most efficiently to where they are needed. Focus on flawless remote operation and administration (no touch required) will become the emerging goal. This will begin the revolution toward truly distributed computing performed and data stored at the edge.
Computing demands have always followed the data; from Mainframe-Terminal, to the Client-Server, Mobile-Cloud, and the emerging IoT-Edge Era. The location of compute has always been based on an economic function Fn(cost of compute cycles, size of data, complexity of data, bandwidth costs). Those variables have driven where we compute since the dawn of computing and will continue into the future. The cost of networking will further begin to drive the realization that not only should compute occur at the edge, but data storage as well. Data should be stored as close as possible to the point of creation. Information from the data may be needed elsewhere, or even replication of some of the data may be elsewhere, but not the general rule. Look for more compute at base stations, retail stores, factories, etc….anywhere large amounts of data is created to make business critical decisions or one wants to create a more real time experience for the consumer. This will also spawn the next generation of hybrid cloud via distribution of processing between edge servers / edge data-centers and centralized data-centers/cloud. The goal will be to find the valuable data near the source (where data is generated), minimize the amount of data that needs to be stored at centralized location (public/private cloud), and deliver results most efficiently to where they are needed. Focus on flawless remote operation and administration (no touch required) will become the emerging goal. This will begin the revolution toward truly distributed computing performed and data stored at the edge.
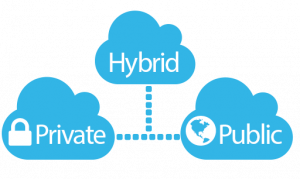 The various cloud models will continue to grow and blur the lines between compute consumption models. Companies will realize these are styles of compute and not based on location. As the ease of use equalizes across (CI, HCI), companies will refine their TCO models finding a need for all three consumption models across different needs. Multi-tenant nature and value of data will continue to raise security concerns in the Public Cloud.
The various cloud models will continue to grow and blur the lines between compute consumption models. Companies will realize these are styles of compute and not based on location. As the ease of use equalizes across (CI, HCI), companies will refine their TCO models finding a need for all three consumption models across different needs. Multi-tenant nature and value of data will continue to raise security concerns in the Public Cloud.
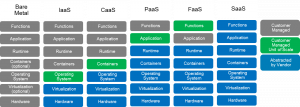 Personally, as Server dudes, we love Software, and Wirth’s law is fantastic J (Wirth’s law, also known as Page’s law, Gates’ law and May’s law, is a computing adage which states that software is getting slower more rapidly than hardware becomes faster). The evolution of infrastructure and software platform models continue adding abstraction. From MaaS (Metal as a Service) to IaaS (Infrastructure as a Service) to SaaS (Software as a Service) to PaaS (Platform as a Service) to CaaS (Container as a Service) to the new FaaS (Function as a Service). The goal of all of these models is to continue SW abstractions to aide in application agility, development speed (devOps), deployment, orchestration, and management of application lifecycles. FaaS is positioned to be quickly adopted for green field applications while CaaS will likely take over as the predominate deployment within an IaaS or PaaS environment for legacy applications. Now the funny thing, especially in the machine learning space, we see more and more MaaS pick up to eke out every last bit of performance. You know the old saying, what is new is old and old is new again.
Personally, as Server dudes, we love Software, and Wirth’s law is fantastic J (Wirth’s law, also known as Page’s law, Gates’ law and May’s law, is a computing adage which states that software is getting slower more rapidly than hardware becomes faster). The evolution of infrastructure and software platform models continue adding abstraction. From MaaS (Metal as a Service) to IaaS (Infrastructure as a Service) to SaaS (Software as a Service) to PaaS (Platform as a Service) to CaaS (Container as a Service) to the new FaaS (Function as a Service). The goal of all of these models is to continue SW abstractions to aide in application agility, development speed (devOps), deployment, orchestration, and management of application lifecycles. FaaS is positioned to be quickly adopted for green field applications while CaaS will likely take over as the predominate deployment within an IaaS or PaaS environment for legacy applications. Now the funny thing, especially in the machine learning space, we see more and more MaaS pick up to eke out every last bit of performance. You know the old saying, what is new is old and old is new again.
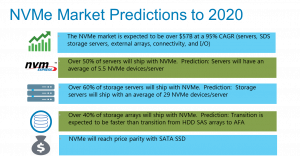 Need more be said….NVMe & SSD’s will displace rotating disks in Servers. From boot drives to high performance IOP monsters to super capacity. They simply make sense and the cost points/sizes make it a no brainer given the gains. And case in point, NVMe SSD have already reached price parity with SAS SSD.
Need more be said….NVMe & SSD’s will displace rotating disks in Servers. From boot drives to high performance IOP monsters to super capacity. They simply make sense and the cost points/sizes make it a no brainer given the gains. And case in point, NVMe SSD have already reached price parity with SAS SSD.
 2018 will see a definite shift in terms of security and the continuation of 2017 initiatives. For example, the Dell PowerEdge 14G server family now has a cryptographic security architecture where part of a key value pair is immutable, unique, and set in the hardware during the system fabrication process. This method provides an indisputable root of trust embedded in the hardware which eliminates the “man in the middle” opportunity all the way from manufacture of server to delivery to customer, and from power-on to the transfer of control to the operating system. The term security, seems incomplete considering the scope of today’s need especially in lights of recently exposed security holes present in all modern CPU architectures. 2018 will see security expand to what is better termed as system-wide protection, integrity verification and automated remediation. While impenetrability is always the objective, with the increasing complexity and sophistication of attackers, it is very likely that additional vulnerabilities and exploits will emerge. As recently seen, remediation can be extremely costly in terms of performance causing a reemergence of single tenancy in some environments. One of the 2018 objectives will be holding a successful intrusions harmless. In other words, if someone can get into the platform, making sure they cannot obtain meaningful information or do damage. This will lead to a more intense trust strategy based on more identity management. Identity at all level (user, device, and platform) will be a great focus and require a complete end-to-end trust chain for any agency that is able to install executables on the platform and policy tools for ensuring trust. This will likely include options based on block chain. Emerging standards like Gen-Z where keys are embedded in the transaction layer will also be required. In open environments where any user can run code, this struggle for “who is ahead” is likely to continue. Greater focus on encryption will emerge requiring any data at rest to be encrypted. (However, even this does not eliminate the risk associated with recent CPU vulnerabilities.) System designers will be forced to trade complications associated with data management and loss of features like deduplication against risk and will cause reconsideration of many software defined strategies to be compared to what is available on focused systems.
2018 will see a definite shift in terms of security and the continuation of 2017 initiatives. For example, the Dell PowerEdge 14G server family now has a cryptographic security architecture where part of a key value pair is immutable, unique, and set in the hardware during the system fabrication process. This method provides an indisputable root of trust embedded in the hardware which eliminates the “man in the middle” opportunity all the way from manufacture of server to delivery to customer, and from power-on to the transfer of control to the operating system. The term security, seems incomplete considering the scope of today’s need especially in lights of recently exposed security holes present in all modern CPU architectures. 2018 will see security expand to what is better termed as system-wide protection, integrity verification and automated remediation. While impenetrability is always the objective, with the increasing complexity and sophistication of attackers, it is very likely that additional vulnerabilities and exploits will emerge. As recently seen, remediation can be extremely costly in terms of performance causing a reemergence of single tenancy in some environments. One of the 2018 objectives will be holding a successful intrusions harmless. In other words, if someone can get into the platform, making sure they cannot obtain meaningful information or do damage. This will lead to a more intense trust strategy based on more identity management. Identity at all level (user, device, and platform) will be a great focus and require a complete end-to-end trust chain for any agency that is able to install executables on the platform and policy tools for ensuring trust. This will likely include options based on block chain. Emerging standards like Gen-Z where keys are embedded in the transaction layer will also be required. In open environments where any user can run code, this struggle for “who is ahead” is likely to continue. Greater focus on encryption will emerge requiring any data at rest to be encrypted. (However, even this does not eliminate the risk associated with recent CPU vulnerabilities.) System designers will be forced to trade complications associated with data management and loss of features like deduplication against risk and will cause reconsideration of many software defined strategies to be compared to what is available on focused systems.
 Hype stays ahead of reality. Composability was a big buzz word in 2017. Unfortunately, as blogged by Dell EMC , the hype is ahead of reality until we get new architectures in place that allow true composability via disaggregation that enable memory centric computing vs CPU centric computing for these new classes of microsecond devices. The industry is on the right path with GenZ but we are still a ways out.
Hype stays ahead of reality. Composability was a big buzz word in 2017. Unfortunately, as blogged by Dell EMC , the hype is ahead of reality until we get new architectures in place that allow true composability via disaggregation that enable memory centric computing vs CPU centric computing for these new classes of microsecond devices. The industry is on the right path with GenZ but we are still a ways out.