Democratizing Accelerated Compute in the Data Center
- September 4, 2019

VMware recently announced[1] their intent to acquire Bitfusion, a start-up in Austin, TX. Bitfusion’s product is called FlexDirect and enables virtual remote attached GPUs, FPGAs, and ASICs for any AI application. The blog states that VMware plans to integrate Bitfusion FlexDirect into the vSphere platform. If you are wondering why this technology is relevant to VMWare, go ahead and count the different accelerator options available or in development today to address the increasing compute requirements of AI applications (Figure 1). As industries are transformed by AI, datacenters will continue to deploy more GPUs (the leading accelerator today for AI) at a rapid pace. Expect the adoption of FPGA and ASICs to increase over time to address the compute requirements for AI. This is no doubt exciting for AI developers and end users that can’t get enough compute to deliver the next AI breakthrough. On the flip side, the complexity of deploying and supporting such a wide range of heterogeneous compute solutions and ensuring it is efficiently used and accessible to all users is not an easy task for IT teams using existing consumption models.

Figure 1. Semiconductor landscape for AI
How are GPUs utilized and consumed by IT teams today?
To understand the opportunity Bitfusion technology brings to AI workloads, let’s review how GPU compute is deployed in the datacenter today for Deep Learning (DL). There are two approaches that are commonly used:
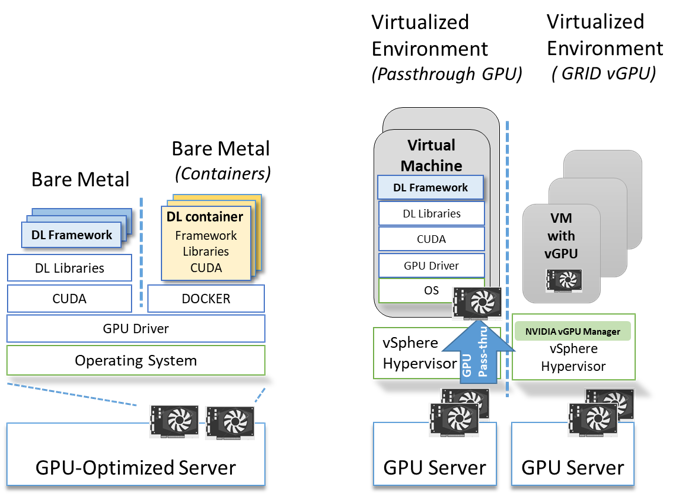
Figure 2 (a) Bare Metal AI stack Figure 2 (b) Virtualized AI compute stack
Figure 2 (A) shows the traditional non-virtualized approach that is typically used to access GPU in bare-metal or native environments. With this approach, the GPU optimized DL software stack consisting of – DL framework, e.g. TensorFlow, PyTorch, Nvidia DL libraries (CuDNN, NCCL) and the CUDA runtime, along with the GPU driver is installed on top of a Server OS (Ubuntu Server/RHEL/CentOS etc). Another option is deployment of the DL software stack as containers on a container run time such as Docker. DL containers are published and available from the DL framework developers (TensorFlow, PyTorch) as well as from Nvidia as tested, optimized, and packaged with compatible software libraries.[2] Containers for DL are becoming increasingly popular among the DL community. Bare metal deployment and containers is a straightforward deployment option, therefore commonly used for systems dedicated to a single user or shared between a small number of users.
Figure 2 (B) show the various options available to consume GPUs inside a Virtual Machine (VM). IT organizations where workload consolidation is the norm and production workloads have been virtualized to run on VMs can virtualize their AI workloads using GPU passthrough or by leveraging Nvidia GRID. A GPU enabled VM using PCIe passthrough is commonly used in cloud deployments to leverage exiting IaaS automation and processes (AWS, GCP and Azure GPU instances). Virtualized GPUs using Nvidia GRID are commonly used for VDI and remote desktop use cases, however they are not widely used for compute workloads. Expect this to change given that the latest GRID software from Nvidia (GRID 9.0) introduces a new vGPU profile (vComputeServer) and licensing policy for AI and data center HPC workloads[3]. Ease of management, security and improved utilization of GPU resources are some of the benefits from virtualizing GPU accelerated AI workloads.
To summarize, Figure 2 shows that IT teams have multiple choices regarding providing GPU accelerated infrastructure for their end users. The options vary in terms of the ease of deployment, management and resource sharing capabilities. GPUs are a very expensive and coveted resource and it is important that IT teams have a solution that maximizes resource utilization.
What are other approaches coming down the road?
Intel CXL (an interconnect standard proposed by Intel leveraging PCIe Gen5) will enable composing a heterogenous computing infrastructure that allows CPUs, GPUs, FPGAs, ASIC or any PCIe device that can go on a PCIe port as a cohesive system. Dell EMC is one of the founding members of the Gen-Z consortium. Gen-Z is a new universal interconnect that would enable composing powerful computer architectures and make true disaggregation a reality. Soon Gen-Z fabric will have all the components required to fully compose a system from pools of resources including CPUs, memory, storage and accelerators. In the interim, Figure 3 illustrates a disaggregated approach for GPU consumption that is feasible today using existing technologies. There are two approaches to compose infrastructure dynamically for consumption – using PCIe or Network as a fabric over which the devices to be consumed are accessed on-demand in an elastic fashion. This approach provides better management and the ability to pool and allocate resources between groups and ability to spin up and down resources based on demand.
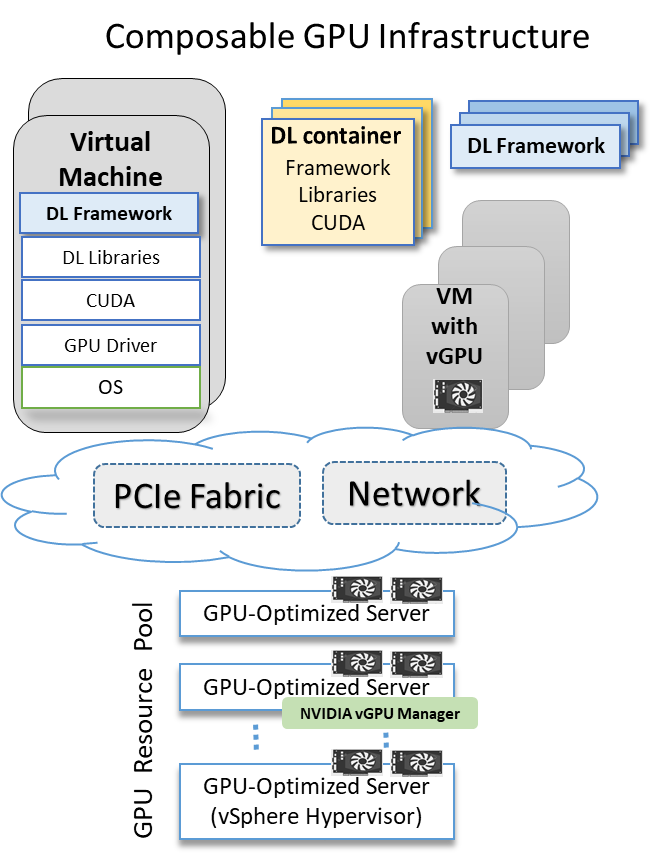
Figure 3. Composable acceleration for AI
Approaches that use the PCIe fabric to provide a composable solution include Liqid[4] and H3 platform[5]. These solutions enable adding PCIe devices like GPUs, FPGAs and NVMe drives to bare metal servers over a PCIe fabric built using their switch and host adapters on the compute nodes. Bitfusion FlexDirect connects any compute servers remotely, over Ethernet, Infiniband RDMA or RoCE networks to GPU server pools. It operates in the user space and uses a client-server architecture. Each approach has its place. A software only approach is easier to implement and deploy for traditional IT shops with requiring significant investment in additional hardware. A software approach can also be leveraged by AIOps. IDC predicts that by 2022, 75% of IT operations will be supplanted by AI or analytics-driven.
If you are not convinced that disaggregation for accelerators is a game changer, let’s look at some of efficiency metrics for existing GPU clusters. There was a recent study that analyzed GPU utilization metrics across different customer sites that were running AI workloads.[6] It found that expensive GPU resources were woefully underutilized. The two key findings from the study are paraphrased below (along with our recommendations for solving them):
Accelerated Edge deployments is a use case that was not covered in the study, but it will also benefit from disaggregation, pooling and partitioning. Using virtualization technology to carve up resources dynamically based on workload requirements will be extremely useful for power sensitive accelerated edge devices.
Enabling the AI Revolution
As a compute infrastructure provider, we get asked why we promote and advocate a solution that reduces the hardware footprint by increasing efficiencies and improving utilization. This is not new, we faced this as an industry when VMWare offered virtualization solutions for server workloads in early 2000s. We observed storage technologies emerge (NAS, SAN) that enabled performance, capacity and cost points that were not achievable using direct attach solutions – thus enabling customers to purchase more optimized infrastructure. Virtualization, abstraction, pooling and sharing are key enablers that have improved the compute, storage and networking landscape over time. It is an inevitable trend that heterogenous and accelerated compute will eventually follow
In summary, making accelerated compute more efficient and easier to use via disaggregation will 1) enable increased adoption and 2) make it feasible to provide the compute resources required for AI transformation to everyone that needs it.
We look forward to continuing our work with the Bitfusion team and expanding the partnership as it becomes part of the Dell Technologies family. There were a lot of lessons learnt from proof-of-concepts done at customer data centers, live FlexDirect demonstrations provided in the Dell EMC Customer Solutions Center by Guy Laporte (solutions architect), and joint conversations that we had with customers to understand their challenges around enabling efficient accelerated compute infrastructure powered using the latest and greatest accelerator technologies. If you are not familiar with the joint work done by Bitfusion and Dell EMC, here are some references that showcase our collaboration over the last few years:
[1] VMware to Acquire Bitfusion, July 18 2019 https://blogs.vmware.com/vsphere/2019/07/vmware-to-acquire-bitfusion.html
[2] Nvidia NGC Containers https://ngc.nvidia.com/catalog/landing
[3] Nvidia GRID 9.0 Documentation https://docs.nvidia.com/grid/latest/
[5] http://www.h3platform.com/
[6] Monitor and Improve GPU Usage for Training Deep Learning Models
https://towardsdatascience.com/measuring-actual-gpu-usage-for-deep-learning-training-e2bf3654bcfd